
Abstract
Abstraction is at the heart of sketching due to the simple and minimal nature of line drawings. Abstraction entails identifying the essential visual properties of an object or scene, which requires semantic understanding and prior knowledge of high-level concepts. Abstract depictions are therefore challenging for artists, and even more so for machines. We present an object sketching method that can achieve different levels of abstraction, guided by geometric and semantic simplifications. While sketch generation methods often rely on explicit sketch datasets for training, we utilize the remarkable ability of CLIP (Contrastive-Language-Image-Pretraining) to distill semantic concepts from sketches and images alike. We define a sketch as a set of Bézier curves and use a differentiable rasterizer to optimize the parameters of the curves directly with respect to a CLIP-based perceptual loss. The abstraction degree is controlled by varying the number of strokes. The generated sketches demonstrate multiple levels of abstraction while maintaining recognizability, underlying structure, and essential visual components of the subject drawn.
Object to Sketch Synthesis with Different Levels of Abstraction

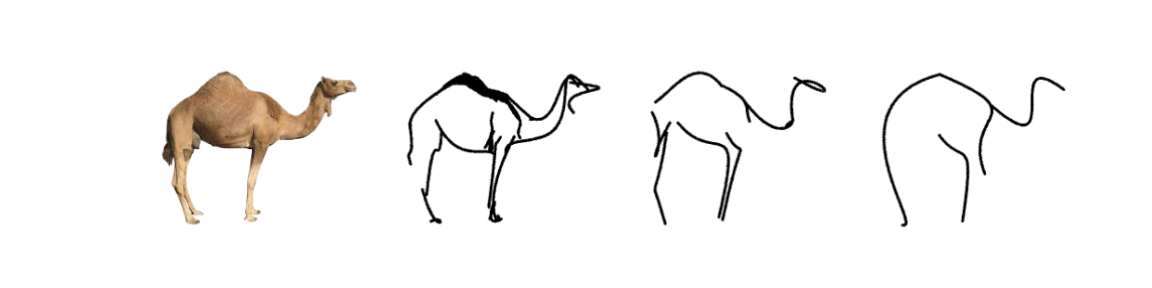
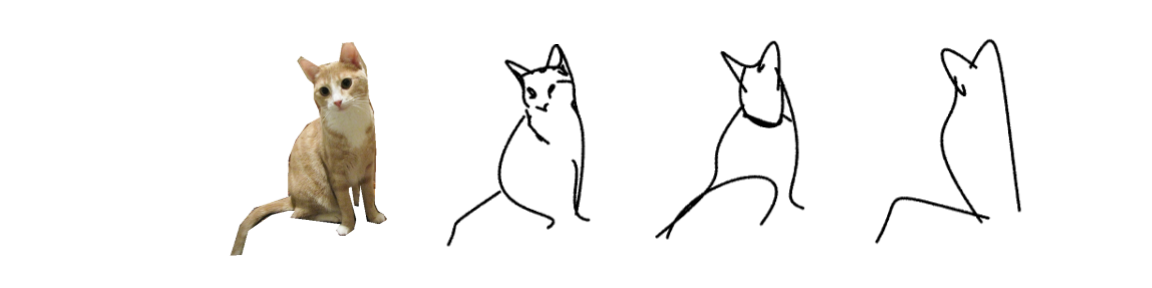
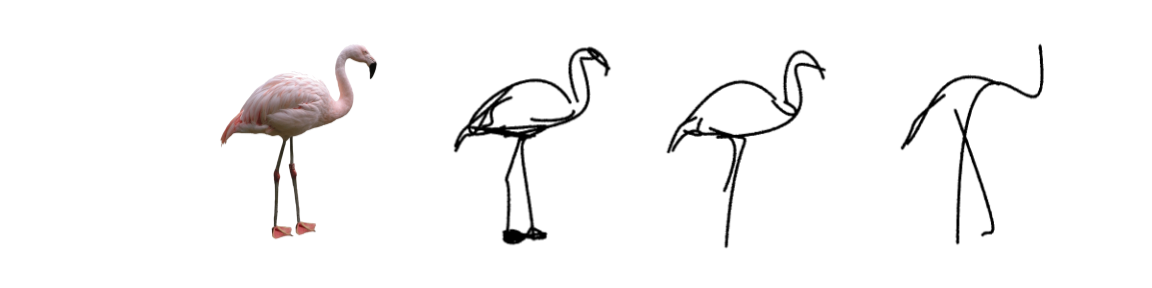
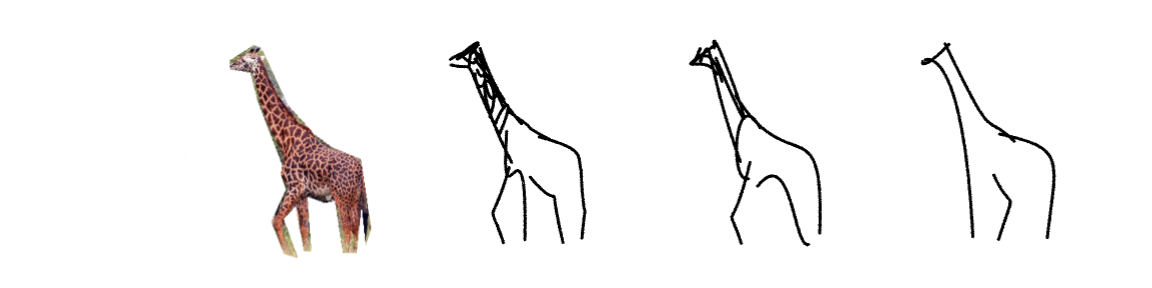
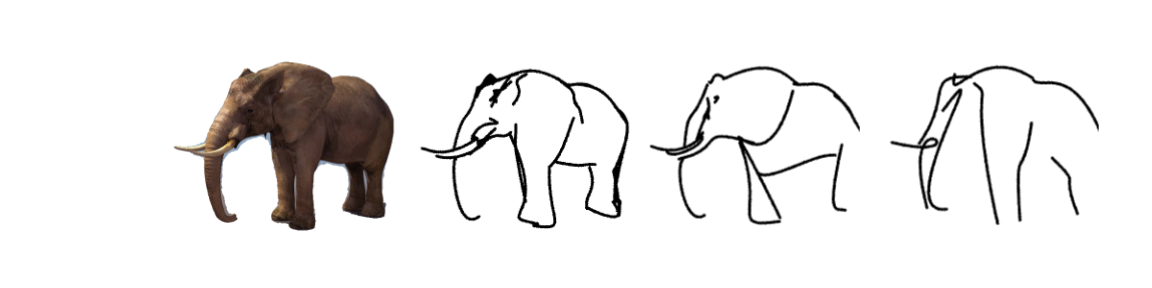
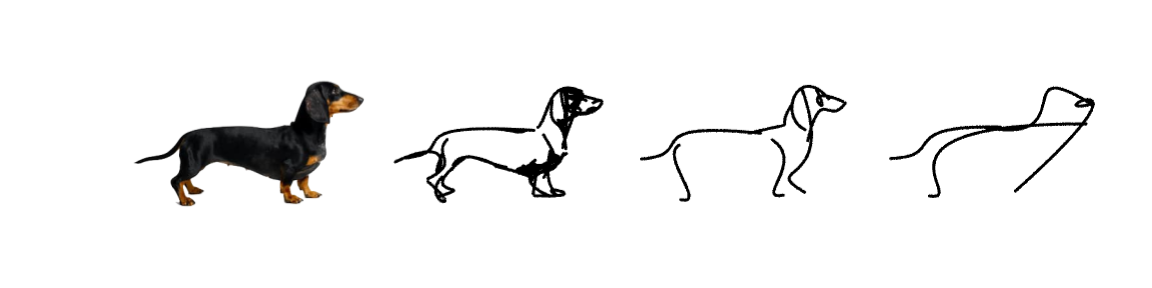

How does it work?
Our method is optimization-based and therefore does not require any explicit sketch dataset. We use the CLIP image encoder to guide the process of converting a photograph to an abstract sketch. CLIP encoding provides the semantic understanding of the concept depicted, while the photograph itself provides the geometric grounding of the sketch to the concrete subject. We define a sketch as a set of N black strokes placed on a white background. We vary the number of strokes N to create different levels of abstraction.
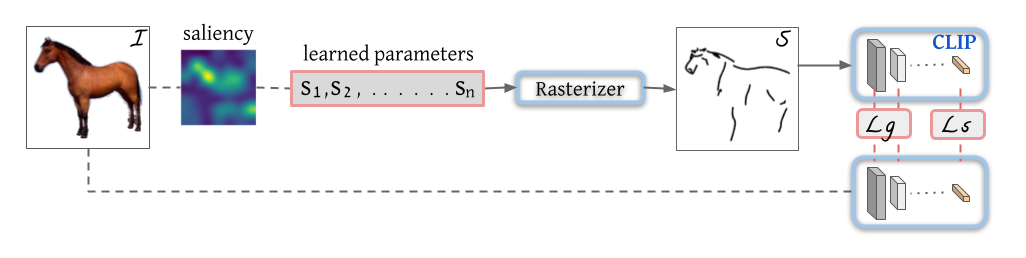
Given a target image I of the desired subject, our goal is to synthesize the corresponding sketch S while maintaining both the semantic and geometric attributes of the subject. We begin by extracting the salient regions of the input image to define the initial locations of the strokes. Next, in each step of the optimization we feed the stroke parameters to a differentiable rasterizer to produce the rasterized sketch. The resulting sketch, as well as the original image are then fed into CLIP to define a CLIP-based perceptual loss. The key to the success of our method is to use the intermediate layers of a pretrained CLIP model to constrain the geometry of the output sketch. Without this term, the output sketch would not be similar to the input image. We back-propagate the loss through the differentiable rasterizer and update the strokes' control points directly at each step until convergence of the loss function. The learned parameters and loss terms are highlighted in red, while the blue components are frozen during the entire optimization process, solid arrows are used to mark the backpropagation path.
Our approach is different from conventional sketching methods in that it does not utilize a sketch dataset for training, rather it is optimized under the guidance of CLIP. Thus, our method is not limited to specific categories observed during training, as no category definition was introduced at any stage. This makes our method robust to various inputs.
Editing the Brush Style on SVGs



Sketching "in the wild": results of 100 random images of cats from SketchCOCO

BibTeX
@article{vinker2022clipasso,
author = {Vinker, Yael and Pajouheshgar, Ehsan and Bo, Jessica Y. and Bachmann, Roman Christian and Bermano, Amit Haim and Cohen-Or, Daniel and Zamir, Amir and Shamir, Ariel},
title = {CLIPasso: Semantically-Aware Object Sketching},
year = {2022},
issue_date = {July 2022},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {41},
number = {4},
issn = {0730-0301},
url = {https://doi.org/10.1145/3528223.3530068},
doi = {10.1145/3528223.3530068},
journal = {ACM Trans. Graph.},
month = {jul},
articleno = {86},
numpages = {11},
keywords = {vector line art generation, sketch synthesis, image-based rendering}
}